
Probably many people know what OLX is. In Russia, the company was absorbed by Avito. However, OLX still exists in many other countries: Ukraine, Poland, Kazakhstan, and many others. A complete list of countries can be found on the main site OLX.
Modified on 01 Feb 2020. Added functionality to bypass cases when proxy is banned
Since all the OLX sites are usually built on the same framework, the web scraper that we code can theoretically work with the website in any country. There may be exceptions of course, but as a rule, everything should work. Therefore, we are going to use OLX Ukraine as a base, and after we have the web scraper ready, we will test it with other sites as well.
So, we will begin with the catalog. We
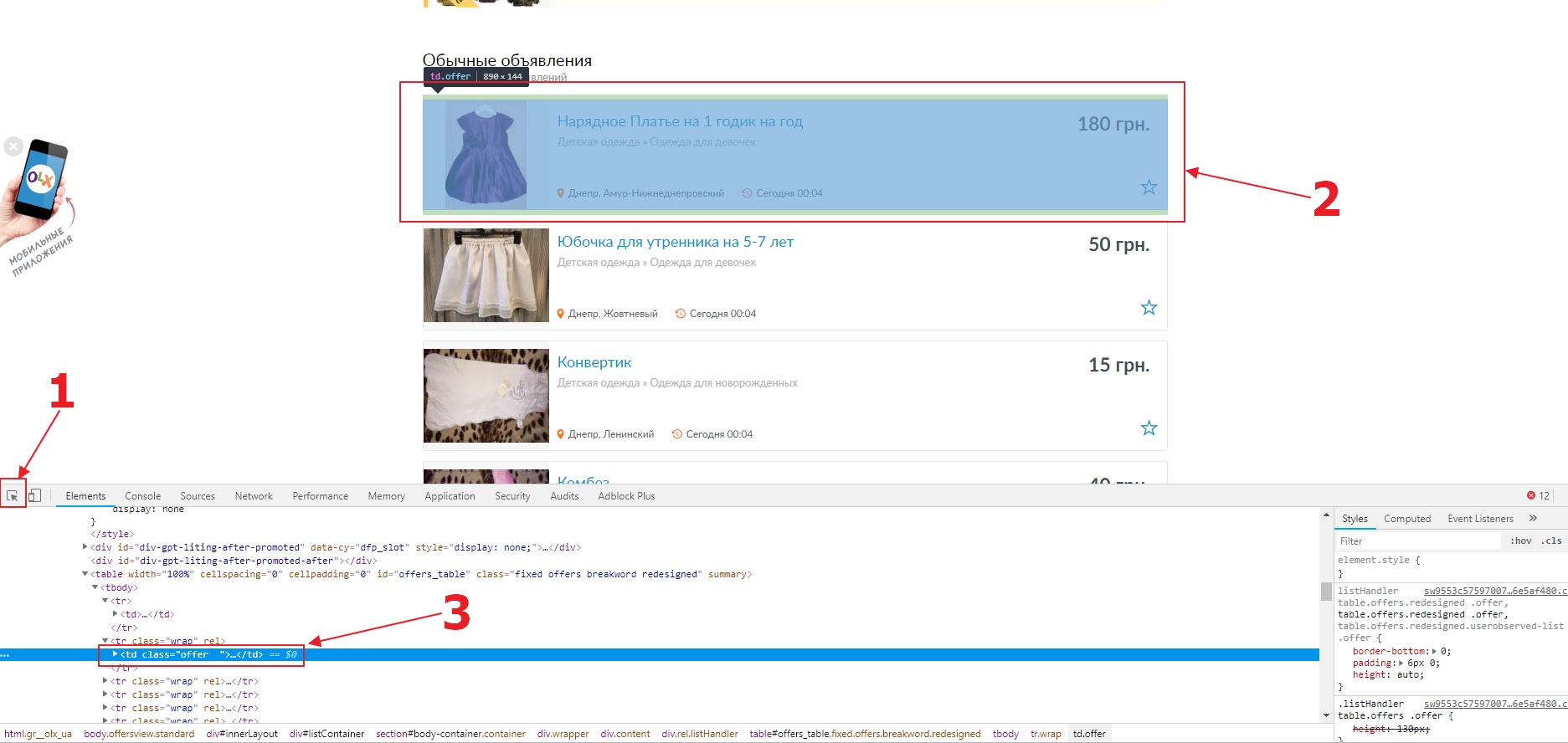
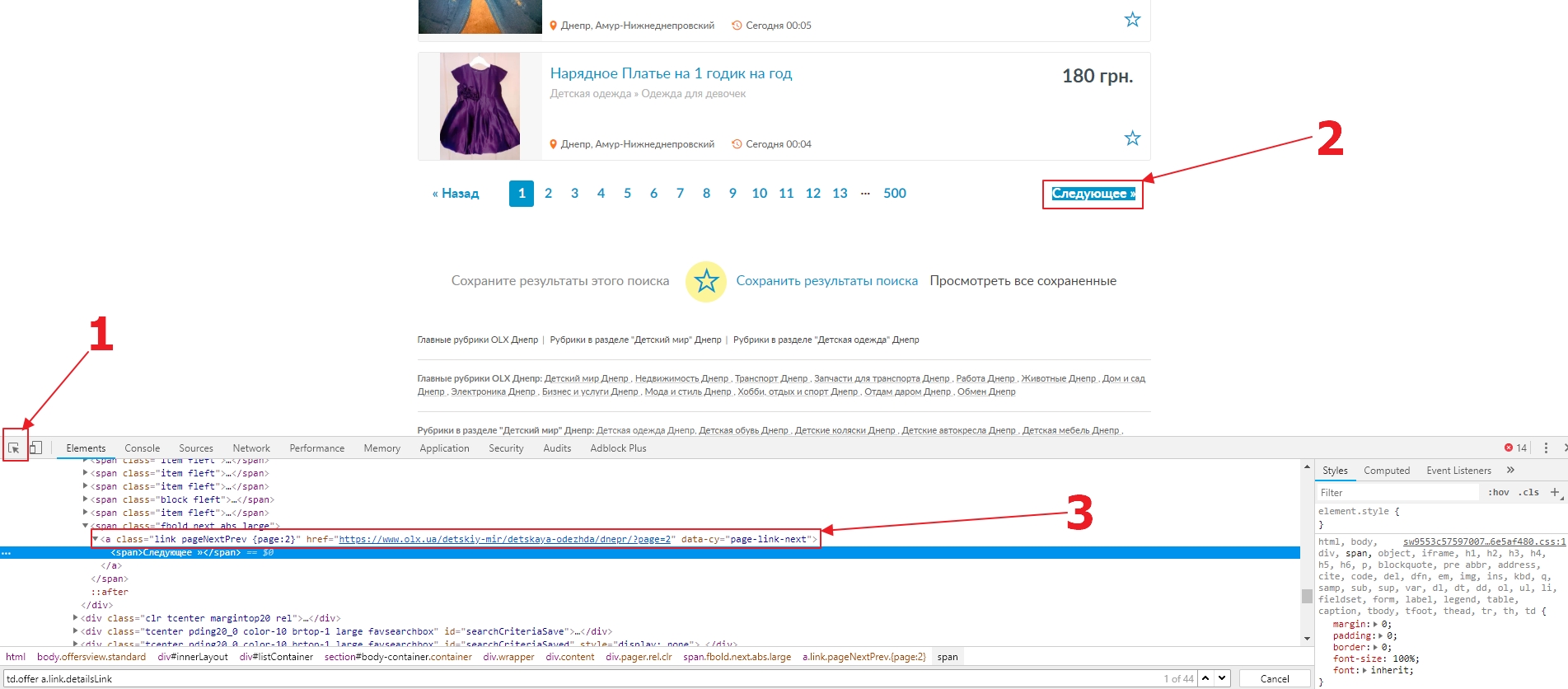
should understand how the navigation between the pages of one section works. Find where to get links to pages with a specific ad. Choose a random category: Children’s clothing. Open the page in Chrome, and enable the developer tools. Go to the Elements tab, and select a tool to inspect the item on the page (1). Click on the block we are interested in with the first item in the list (2), then, in the HTML code in the “Elements” tab, you should be able to see selected HTML node (3).
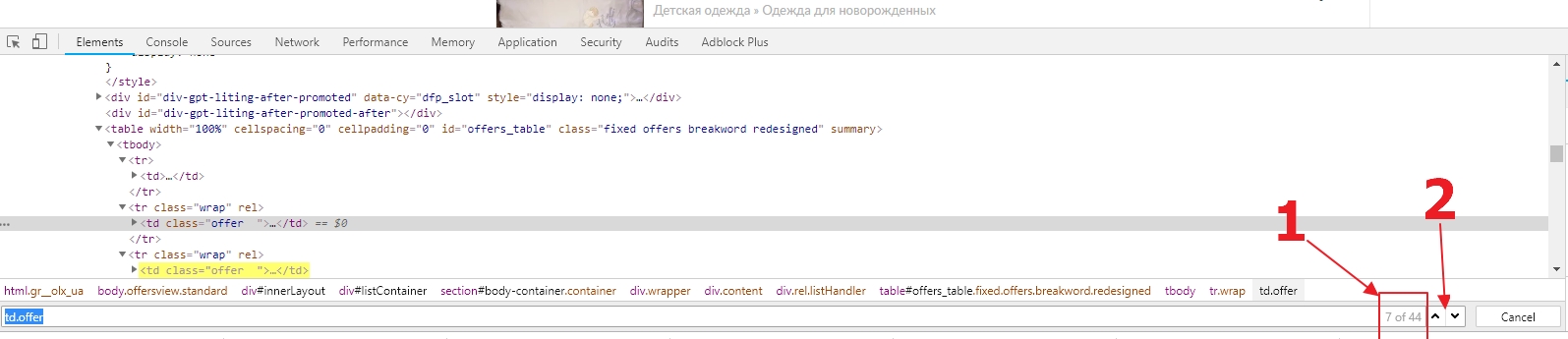
We may be able to use td.offer as the CSS selector to select a block, but first, we need to make sure of that. To do it, press CTRL + F, while you are in the HTML code of the “Elements” tab. Let’s type our selector in the search bar. If you do everything correctly, then you should see that 44 elements (1) have been found. To check if the selector has not taken something extra, simply use the up and down buttons (2) and see what nodes are selected. If you want to exclude ads in the top (which are promoted for money), you can use the following selector: td.offer: not (.promoted).
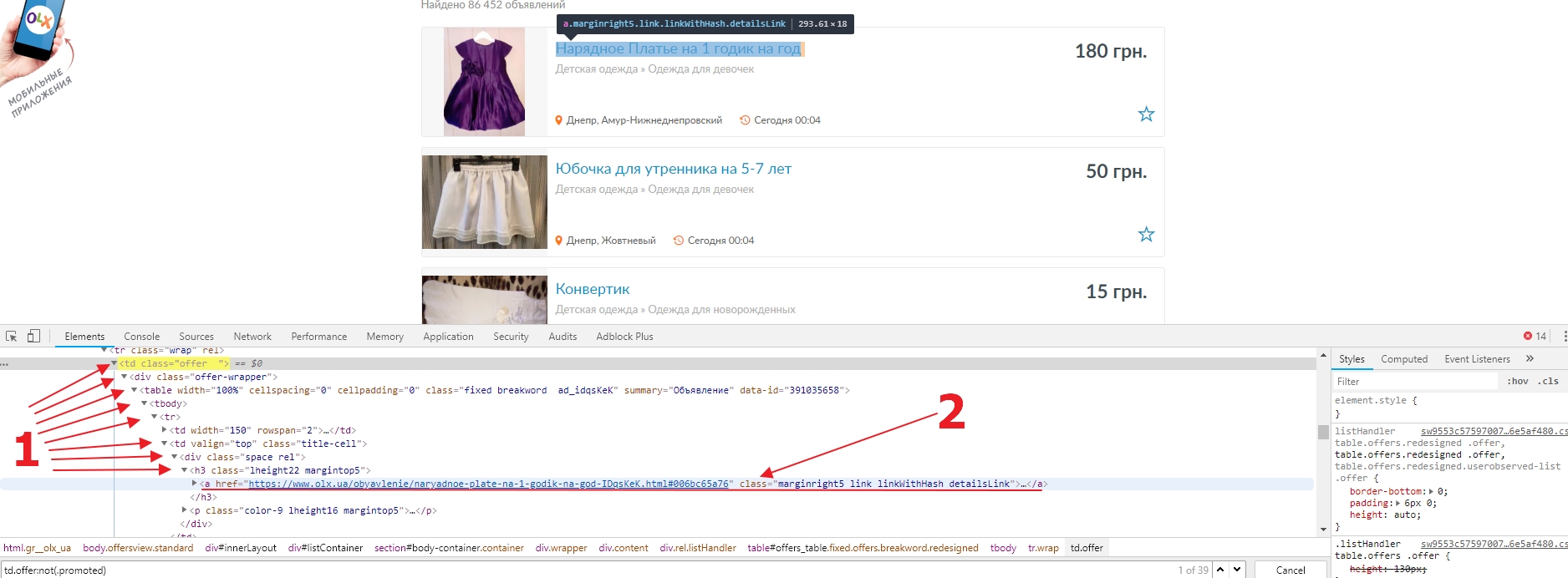
However, we do not need the block itself, but a link to the ad page. Therefore, let’s open the HTML elements (1) and find the link we need (2). Thus, our selector for links to ads pages will be td.offer a.link.detailsLink. We need to check and make sure that there are exactly 44 links. In different versions of OLX, there may be different formatting of blocks with ads, so we can use the a.link.detailsLink selector for better compatibility.
Let’s check the paginator. Doing the same as we found the elements with the ad, we are going to find the link to the next page in the paginator (3). And we get the selector a[data-cy="page-link-next"]. Let’s make sure that there is just single element with such selector on the page.
Now we have everything to describe the scraping logic for the specific category. To navigate through the pages of the category we are planning to use link pool. This will allow us to use the same code for all pages of the category. Therefore, our scraper looks like:
---
config:
agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36
debug: 2
do:
# Push start URL to the pool
- link_add:
url: https://www.olx.ua/detskiy-mir/detskaya-odezhda/dnepr/
# Iterate over the pool and load each link
- walk:
to: links
do:
# Find the link to the next page
- find:
path: a[data-cy="page-link-next"]
do:
# Parse link from href attribute
- parse:
attr: href
# Add it to the pool
- link_add
# Find a link to an ad
- find:
path: a.link.detailsLink
do:
# Parse URL from href attribute
- parse:
attr: href
# We are not going to do anything with it for now
This code will go through all the pages of the catalog, go into blocks with ads and parse a link to the ad page from there.
Now we need to describe the logic of data collection from the ad page. To do it, open any ad and find CSS selectors to blocks you want to extract same way as we did for catalog page.
- Selector for ad block on page:
div#offer_active. We will initially switch to this block so that in case of its absence we would not create an empty object. - Ad title:
h1. Note that selectors are built relative to the current block (div#offer_active). - Address:
address > p - Ad ID:
em > small(we need to filter data when parsing content to remove extra text) - Date and time of ad placement:
em(you will need to delete nodes “a” and “small” before parsing, and also to clear the data a bit) - We have a table with details, but the fields there may be different, depending on the type of ad. Therefore, we will collect field names and values. A detailed explanation will be in the code, and a selector for this table is
table.details. - Description:
div#textContent - Image:
div#photo-gallery-opener > img(since we need a full-sized image, we’ll have to cut off the part of the URL that contains the image size. We are going to use the filter.) - Price:
div.price-label - Seller Name:
div.offer-user__details > h4 - Phone: there is no phone on the page. To scrape it, we will have to make an additional request. We get back to it a bit later.
Let’s code part of the scraper which will collect all the data from the ad page, except for the phone number (for now) and see what we get in the dataset:
---
config:
agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36
debug: 2
do:
# Push start URL to the pool
- link_add:
url: https://www.olx.ua/detskiy-mir/detskaya-odezhda/dnepr/
# Iterate over the pool and load each link
- walk:
to: links
do:
# Find the link to the next page
- find:
path: a[data-cy="page-link-next"]
do:
# Parse link from href attribute
- parse:
attr: href
# Add it to the pool
- link_add
# Find a link to an ad
- find:
path: a.link.detailsLink
do:
# Parse URL from href attribute
- parse:
attr: href
# Load page with the ad
- walk:
to: value
do:
# Find common container for the ad
- find:
path: 'div#offer_active'
do:
# Create data object with name item
- object_new: item
# Find element with ad title
- find:
path: h1
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save data to the item data object field
- object_field_set:
object: item
field: title
# Find element with ad description
- find:
path: 'div#textContent'
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save data to the item data object field
- object_field_set:
object: item
field: description
# Find element with ad ID
- find:
path: 'em > small'
do:
# Parse text content using the filter. Since ID consist with digits only, we will apply filter to extract only digits.
- parse:
filter: (\d+)
# Save data to the item data object field
- object_field_set:
object: item
field: ad_id
# Find element with ad date and time
- find:
path: 'em'
do:
# Remove nodes with not relevant information
- node_remove: a,small
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Remove trailing comma
- normalize:
routine: replace_substring
args:
\,$: ''
# Save data to the item data object field
- object_field_set:
object: item
field: date
# Find element with ad price
- find:
path: div.price-label
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save data to the item data object field
- object_field_set:
object: item
field: price
# Find element with seller name
- find:
path: div.offer-user__details > h4
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save data to the item data object field
- object_field_set:
object: item
field: seller
# Find element with address
- find:
path: address > p
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save data to the item data object field
- object_field_set:
object: item
field: address
# Find element with image
- find:
path: div#photo-gallery-opener > img
do:
# Parse content of src attribute and filter it to cut the end with size
- parse:
attr: src
filter: ^([^;]+)
# Save data to the item data object field
- object_field_set:
object: item
field: image
# Let's also save ad URL to the data object
# we will use content of static variable "url" for it
- static_get: url
# Save data to the item data object field
- object_field_set:
object: item
field: url
# Now let's get data from the table with item details
- find:
path: table.details
do:
# Find all table rows which has child cell with class "value"
- find:
path: tr:haschild(td.value)
do:
# Switch to th to get field name
- find:
path: th
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save content to the variable "fieldname"
- variable_set: fieldname
# Switch to td to get field data
- find:
path: td
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save data to the field defined by name kept in the "fieldname" variable of the "item" object
- object_field_set:
object: item
field: <%fieldname%>
# Save object item to the dataset
- object_save:
name: item
# Exit here to ensure all data is collected
- exit
As result we get the following record in the dataset:
[{
"item": {
"ad_id": "574946238",
"address": "Днепр, Днепропетровская область, Индустриальный",
"date": "в 22:06, 9 февраля 2019",
"description": "СОСТОЯНИЕ НОВОГО. Деффектов никаких нет. Без следов носки. Брендовый красивенный демисезонный комбинезон F&F (Англия) для мальчика 3-6 мес. Сезон весна, сразу как снимите зимний паркий комбинезон. Покупкой будете очень довольны- эта вещь Вас действительно порадует. Качество английское, а значит супер, приятная ткань, швы не торчат. Утеплитель и подкладка в идеале. Из новой коллекции, яркий принт. На малыше смотрится бомбезно. Удобный, легко одевается- продольная молния, НЕ кнопки. Моделька очень удачная, эргономичная, правильного покроя- чётко сидит по фигуре (не висит мешком). Внутри до середины утеплён флисом (подходит и на холодную весну). Перед продажей постиран- чистенький - можно сразу носить. В комплект входят варежки и фирменная деми шапочка Early Days в тон к комбезу (двойная вязка) - состояние новой, БЕЗ катышек. Глубокая, хорошо прикрывает ушки, не сползает. Продажа только комплектом. Замеры: длина от плеча до пяточки по спинке 61; от шеи до пяточки по спинке 62; от шеи до памперса по спинке 44; от верха капюшона до пяточки по спинке 81; ПОГ от подмышки до подмышки 34; рукав от плеча 23; рукав от шеи 29; ширина в плечах 28; шаговый от памперса до пяточки 21. Пересылаю. Смотрите все мои объявления Есть точно такой же комбинезон в размере 0-3 мес. (покупала ростовкой для сына и племяша). Смотрите в моих объявлениях На 3-6 мес. есть еще серебристый комбез чуть полегче. Есть комбинезоны на другой возраст. Есть пакеты фирменной одежды для мальчика 0-6 мес. Также продам курточки на старший возраст, жилетки Спрашивайте, не всё выставлено. Скину фото что есть. Можно писать и в Viber. Отвечаю сразу",
"image": "https://apollo-ireland.akamaized.net:443/v1/files/yxyp673xu3zj2-UA/image",
"price": "600 грн.",
"seller": "BRAND CLOTHING",
"title": "Комбинезон F&Fдемисезонный 3-6 мес. Весна next gap деми + шапка",
"url": "https://www.olx.ua/obyavlenie/kombinezon-f-fdemisezonnyy-3-6-mes-vesna-next-gap-demi-shapka-IDCUpMq.html#006bc65a76;promoted",
"Объявление от": "Частного лица",
"Размер": "68",
"Состояние": "Б/у",
"Тип одежды": "Одежда для мальчиков"
}
}]
Everything is fine, so now we will see how we can collect the phone number. To do it, open the page with the ad, then the developer tools, and go to the Network tab (1). Inside the tab, we only want to see XHR requests (2) and click on clear all requests button. Then click on the “Show Phone” button (3). We will see that the browser has made a request to the server (4).
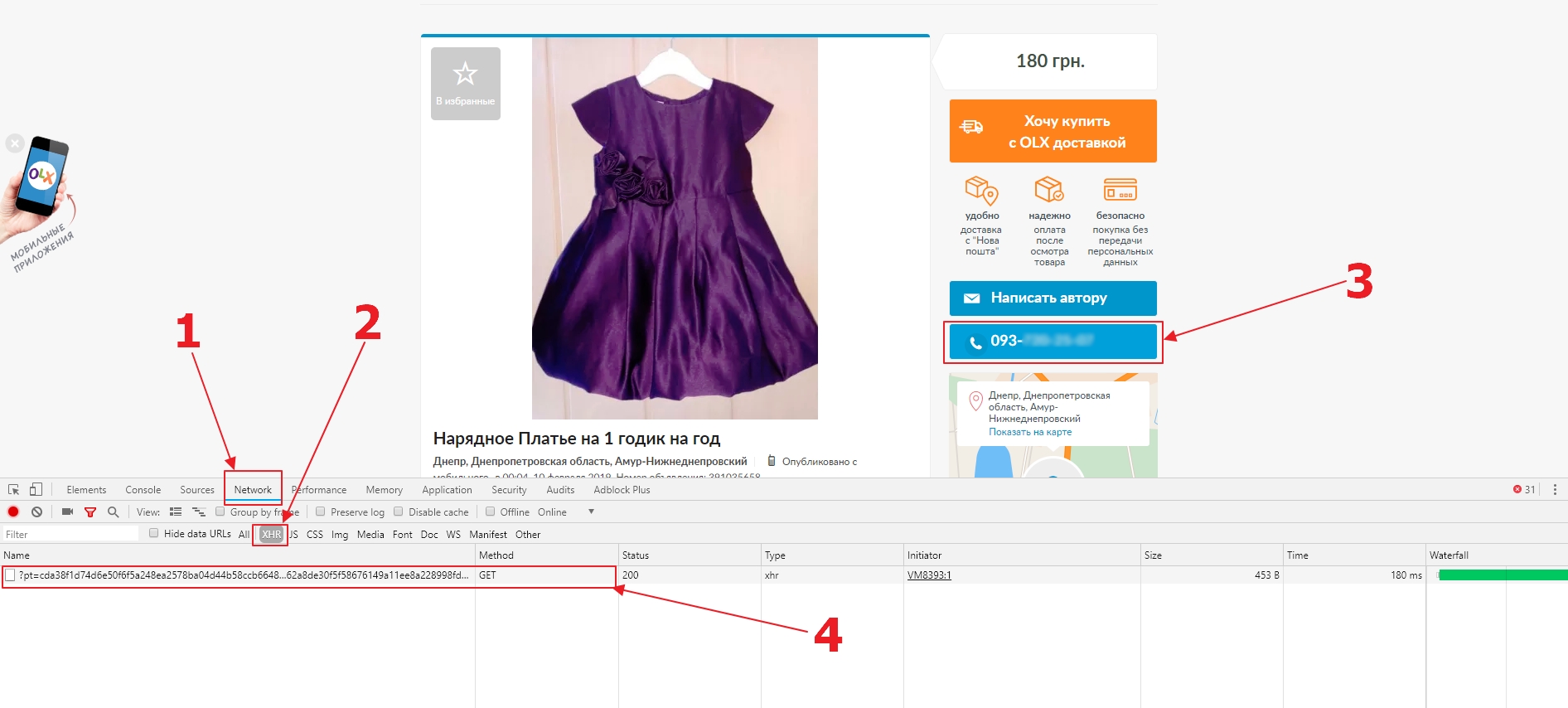
Now open the request and see the address (1) where it is sent and what data (2) it sends.

Now we have the URL: https://www.olx.ua/ajax/misc/contact/phone/qsKeK/
and parameter pt
cda38f1d74d6e50f6f5a248ea2578ba04d44b58ccb6648718ce825a15dd1c036494b2cd1c6cb27762a8de30f5f58676149a11ee8a228998fd7f6b8cde5bb83a9
Obviously, in order to emulate such request, we need to have the ad ID (which is qsKeK in this particular case) and the parameter pt. If we search for them in the page source (“Elements” tab), we find that the pt parameter is in JavaScript on the page, which means we can extract it using a regular expression. The ad ID can be pulled from the “Show Phone” button. It will also give us the opportunity to pick up phones only if this button exists on the page. The logic will be simple, we will go into the node with the button and do certain actions, and if the button does not exist, then the actions will not be performed. Let’s make changes to our scraper and add a snippet to collect the phone number.
---
config:
agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36
debug: 2
do:
# Push start URL to the pool
- link_add:
url: https://www.olx.ua/detskiy-mir/detskaya-odezhda/dnepr/
# Iterate over the pool and load each link
- walk:
to: links
do:
# Find the link to the next page
- find:
path: a[data-cy="page-link-next"]
do:
# Parse link from href attribute
- parse:
attr: href
# Add it to the pool
- link_add
# Find a link to an ad
- find:
path: a.link.detailsLink
do:
# Parse URL from href attribute
- parse:
attr: href
# Load page with the ad
- walk:
to: value
do:
# Find common container for the ad
- find:
path: 'div#offer_active'
do:
# Create data object with name item
- object_new: item
# Find element with ad title
- find:
path: h1
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save data to the item data object field
- object_field_set:
object: item
field: title
# Find element with ad description
- find:
path: 'div#textContent'
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save data to the item data object field
- object_field_set:
object: item
field: description
# Find element with ad ID
- find:
path: 'em > small'
do:
# Parse text content using the filter. Since ID consist with digits only, we will apply filter to extract only digits.
- parse:
filter: (\d+)
# Save data to the item data object field
- object_field_set:
object: item
field: ad_id
# Find element with ad date and time
- find:
path: 'em'
do:
# Remove nodes with not relevant information
- node_remove: a,small
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Remove trailing comma
- normalize:
routine: replace_substring
args:
\,$: ''
# Save data to the item data object field
- object_field_set:
object: item
field: date
# Find element with ad price
- find:
path: div.price-label
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save data to the item data object field
- object_field_set:
object: item
field: price
# Find element with seller name
- find:
path: div.offer-user__details > h4
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save data to the item data object field
- object_field_set:
object: item
field: seller
# Find element with address
- find:
path: address > p
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save data to the item data object field
- object_field_set:
object: item
field: address
# Find element with image
- find:
path: div#photo-gallery-opener > img
do:
# Parse content of src attribute and filter it to cut the end with size
- parse:
attr: src
filter: ^([^;]+)
# Save data to the item data object field
- object_field_set:
object: item
field: image
# Let's also save ad URL to the data object
# we will use content of static variable "url" for it
- static_get: url
# Save data to the item data object field
- object_field_set:
object: item
field: url
# Now let's get data from the table with item details
- find:
path: table.details
do:
# Find all table rows which has child cell with class "value"
- find:
path: tr:haschild(td.value)
do:
# Switch to th to get field name
- find:
path: th
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save content to the variable "fieldname"
- variable_set: fieldname
# Switch to td to get field data
- find:
path: td
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save data to the field defined by name kept in the "fieldname" variable of the "item" object
- object_field_set:
object: item
field: <%fieldname%>
# Find the script element with phonetoken (we need to lookup in whole document as currently we are in the block without this script tag)
- find:
in: doc
path: script:contains("phoneToken")
do:
# Parse only token using regular expression
- parse:
filter: \'([^']+)\'
# Save value to the variable
- variable_set: token
# Find the "Show phone" button
- find:
path: li.link-phone
do:
# Parse ID of the ad
- parse:
attr: class
filter: \'id\'\:\'([^']+)\'
# Save value to the variable
- variable_set: id
# Do random pause from 5 to 10 sec
- sleep: 5:10
# Send request to the server
- walk:
to: https://www.olx.ua/uk/ajax/misc/contact/phone/<%id%>/?pt=<%token%>
headers:
accept: '*/*'
accept-language: ru-RU,ru;q=0.9,en-US;q=0.8,en;q=0.7
x-requested-with: XMLHttpRequest
do:
# Exit here to see HTML content we are getting from the server
- exit
# Save object item to the dataset
- object_save:
name: item
If we run the scraper in debug mode, in the log we will see that the server sends us the following structure:
<html><head></head><body><body_safe>
<body_safe>
<value>067-XXX-XX-XX</value>
</body_safe>
</body_safe></body></html>
So, to collect the phone number, we need to use the body_safe > value CSS selector. Let’s add it to our web scraper:
---
config:
agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36
debug: 2
do:
# Push start URL to the pool
- link_add:
url: https://www.olx.ua/detskiy-mir/detskaya-odezhda/dnepr/
# Iterate over the pool and load each link
- walk:
to: links
do:
# Find the link to the next page
- find:
path: a[data-cy="page-link-next"]
do:
# Parse link from href attribute
- parse:
attr: href
# Add it to the pool
- link_add
# Find a link to an ad
- find:
path: a.link.detailsLink
do:
# Parse URL from href attribute
- parse:
attr: href
- variable_set:
field: repeat
value: "yes"
# Load page with the ad
- walk:
to: value
repeat: <%repeat%>
do:
- variable_clear: ok
# Find common container for the ad
- find:
path: 'div#offer_active'
do:
- variable_set:
field: ok
value: 1
# Create data object with name item
- object_new: item
# Find element with ad title
- find:
path: h1
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save data to the item data object field
- object_field_set:
object: item
field: title
# Find element with ad description
- find:
path: 'div#textContent'
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save data to the item data object field
- object_field_set:
object: item
field: description
# Find element with ad ID
- find:
path: 'em > small'
do:
# Parse text content using the filter. Since ID consist with digits only, we will apply filter to extract only digits.
- parse:
filter: (\d+)
# Save data to the item data object field
- object_field_set:
object: item
field: ad_id
# Find element with ad date and time
- find:
path: 'em'
do:
# Remove nodes with not relevant information
- node_remove: a,small
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Remove trailing comma
- normalize:
routine: replace_substring
args:
\,$: ''
# Save data to the item data object field
- object_field_set:
object: item
field: date
# Find element with ad price
- find:
path: div.price-label
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save data to the item data object field
- object_field_set:
object: item
field: price
# Find element with seller name
- find:
path: div.offer-user__details > h4
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save data to the item data object field
- object_field_set:
object: item
field: seller
# Find element with address
- find:
path: address > p
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save data to the item data object field
- object_field_set:
object: item
field: address
# Find element with image
- find:
path: div#photo-gallery-opener > img
do:
# Parse content of src attribute and filter it to cut the end with size
- parse:
attr: src
filter: ^([^;]+)
# Save data to the item data object field
- object_field_set:
object: item
field: image
# Let's also save ad URL to the data object
# we will use content of static variable "url" for it
- static_get: url
# Save data to the item data object field
- object_field_set:
object: item
field: url
# Now let's get data from the table with item details
- find:
path: table.details
do:
# Find all table rows which has child cell with class "value"
- find:
path: tr:haschild(td.value)
do:
# Switch to th to get field name
- find:
path: th
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save content to the variable "fieldname"
- variable_set: fieldname
# Switch to td to get field data
- find:
path: td
do:
# Parse text content
- parse
# Normalize parsed data, depupe and trim whitespaces
- space_dedupe
- trim
# Save data to the field defined by name kept in the "fieldname" variable of the "item" object
- object_field_set:
object: item
field: <%fieldname%>
# Find the script element with phonetoken (we need to lookup in whole document as currently we are in the block without this script tag)
- find:
in: doc
path: script:contains("phoneToken")
do:
# Parse only token using regular expression
- parse:
filter: \'([^']+)\'
# Save value to the variable
- variable_set: token
# Find the "Show phone" button
- find:
path: li.link-phone
do:
# Parse ID of the ad
- parse:
attr: class
filter: \'id\'\:\'([^']+)\'
# Save value to the variable
- variable_set: id
# Do random pause from 5 to 10 sec
- sleep: 5:10
# Send request to the server
- walk:
to: https://www.olx.ua/uk/ajax/misc/contact/phone/<%id%>/?pt=<%token%>
headers:
accept: '*/*'
accept-language: ru-RU,ru;q=0.9,en-US;q=0.8,en;q=0.7
x-requested-with: XMLHttpRequest
do:
# Find element with phone number
- find:
path: body_safe > value
do:
# Parse text
- parse
# Save data to the item data object field
- object_field_set:
object: item
field: phone
# Save object item to the dataset
- object_save:
name: item
- cookie_reset
- find:
path: body
do:
- variable_get: ok
- if:
match: 1
do:
- variable_clear: repeat
else:
- error: Proxy is banned or page layout has been changed
- cookie_reset
- proxy_switch
- cookie_reset
The scraper works well on the OLX Ukraine website and collects all the data we need. But it can also work on other sites. For example, in order for it to work on the OLX Kazakhstan website, you need:
- Change the starting URL in line 8: https://www.olx.kz/kk/moda-i-stil/odezhda/
- Change the URL on line 210 (to pick up the phone number): https://www.olx.kz/kk/ajax/misc/contact/phone//?pt=

стоит заметить что на 10 февраля 2019 (даты публикации статьи) парсер телефонов уже к сожалению не актуален)
Почему же не актуален, если Вы запустите приведенный парсер, Вы увидите что он до сих пор актуален (25 февраля 2019). Если у Вас не получается забрать телефоны, свяжитесь с нами в чате и сообщите ID диггера, попробуем разобраться почему у Вас не работает.
На каком языке это написано?
Заранее спасибо за ответ
Используется собственный мета-язык сервиса diggernaut.com формата Yaml.