

There is a new arrival in the ranks of services for solving captcha supported by us. Meet the 2Captcha.
From the functional side, 2Captcha looks similar to the AntiCaptcha. It supports all popular kinds of captcha from the box, has “proxyless” mode, which is in demand by our users. Prices are on the same level as AntiCaptcha has. However, there is one crucial thing that differs 2Captcha from other captcha solving services. The offer solution for the Google ReCaptcha v3, which is a new kind of Google captcha and already used on some popular websites. We tested it, and it works indeed!
More details about usage of 3rd party providers for captcha resolving you can find in our documentation.
Below we describe how to use 2Captcha to solve Google ReCaptcha v3 using the example of the Russian traffic police website. And we will request information about registrations in the traffic police by VIN.
For a start, let’s go to [russian traffic police site](https: //xn--90adear.xn--p1ai/check/auto/) and make sure that there is ReCaptcha v3 used on the page with the search form. At first glance, the link to api.js from Google is not observed in the source code of the page, so automatic extraction of the site key and the action parameter will not work, and we need to find them manually. If we look at the Network tab in the developer console of your browser (Chrome / Firefox), then we will see that api.js is loaded, which means that the browser doesn’t load it directly from the page source, but use some javascript. Therefore, our task will be to check all loaded JS files on the Network tab.
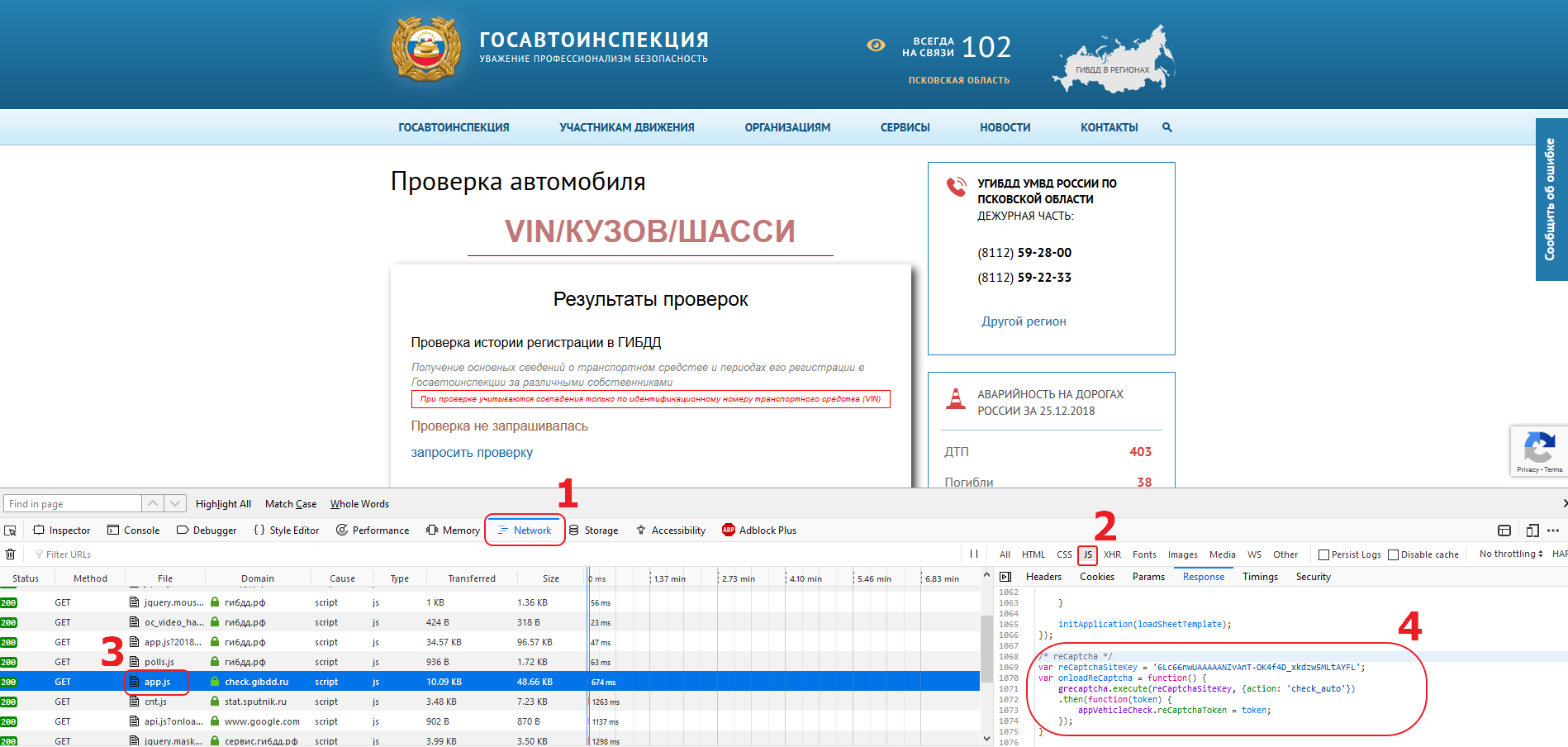
Looking through the code of JS files, we will see that app.js file has a fragment of the code that looks like something we are seeking.
/* reCaptcha */
var reCaptchaSiteKey = '6Lc66nwUAAAAANZvAnT-OK4f4D_xkdzw5MLtAYFL';
var onloadReCaptcha = function() {
grecaptcha.execute(reCaptchaSiteKey, {action: 'check_auto'})
.then(function(token) {
appVehicleCheck.reCaptchaToken = token;
});
}
From this block we can take the site key (6Lc66nwUAAAAANZvAnT-OK4f4D_xkdzw5MLtAYFL) and the action parameter (check_auto).
Next, we need to determine which query the page is doing when we click the search button. To do it, open the developer panel in the browser, go to the Network tab and set the filter so that only XHR requests are shown to us.
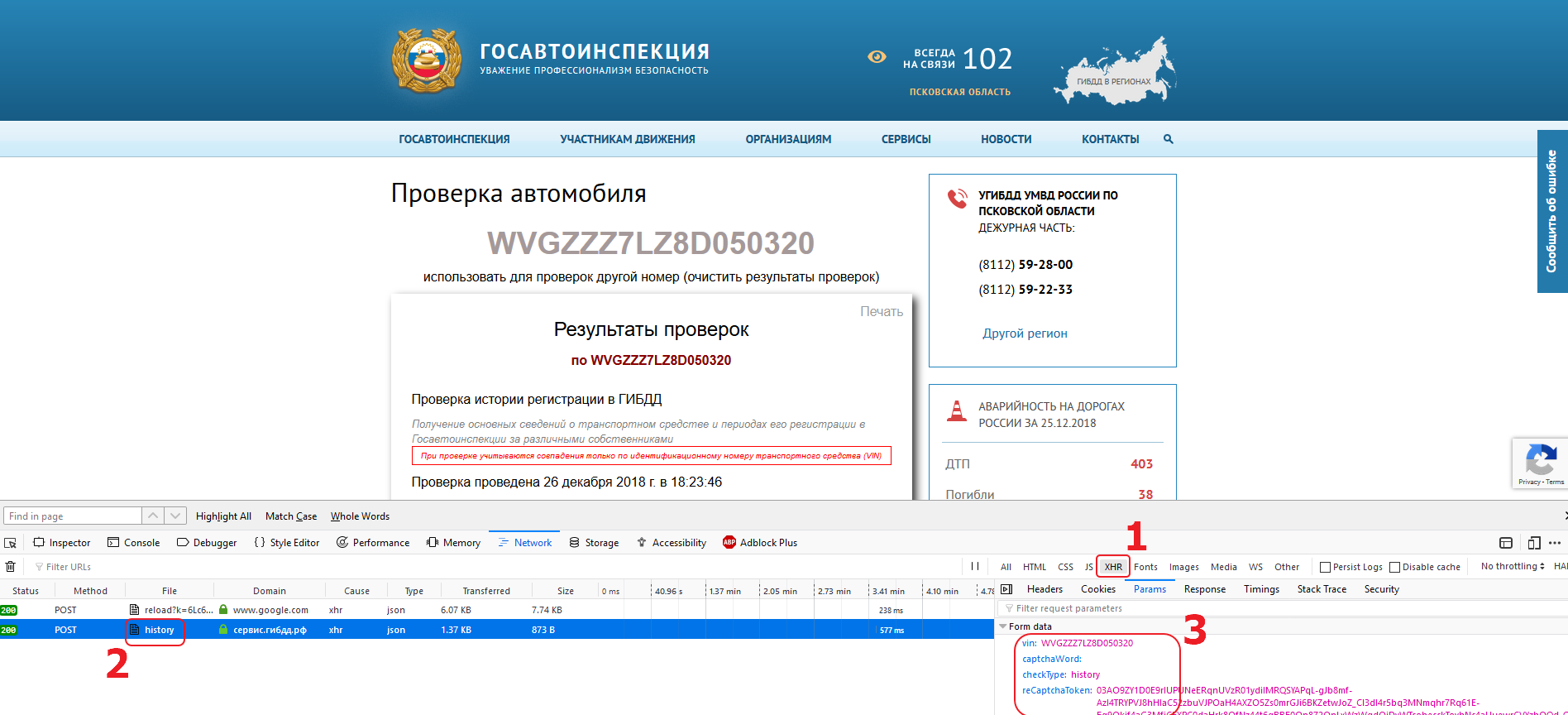
We’ can see that the following resource is being loaded: https: //xn--b1afk4ade.xn--90adear.xn--p1ai/proxy/check/auto/history by the POST method. The VIN, the type of verification and the Google ReCaptcha v3 token are transferred to the server in the request.
Thus, we have everything to build a web scraper. Please note, that to scrape this website you need to use Russian proxy, as they recently closed access to this data to foreign IPs.
---
config:
debug: 2
agent: "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"
proxy: PUT HERE YOUR RUSSIAN PROXY IN 1.1.1.1:8888 FORMAT
do:
# SET VIN TO CHECK TO THE VARIABLE
- variable_set:
field: vin
value: WVGZZZ7LZ8D050320
# LOAD PAGE WITH SEARCH FORM
- walk:
to: https://xn--90adear.xn--p1ai/check/auto/
do:
# РЕШАЕМ КАПЧУ
- captcha_resolve:
provider: 2captcha
type: recaptchav3
apikey: HERE YOU SHOULD SET YOUR OWN 2CAPTCHA API KEY
sitekey: 6Lc66nwUAAAAANZvAnT-OK4f4D_xkdzw5MLtAYFL
minscore: 0.3
action: check_auto
# GO TO BODY BLOCK ON THE BAGE TO SWITCH TO THE BLOCK CONTEXT
- find:
path: body
do:
# READ VARIABLE captcha TO THE REGISTER
- variable_get: captcha
# IF THERE IS TOKEN, CAPTCHA WAS RESOLVED AND WE CAN DO QUERY AND GET DATA
- if:
match: \S
do:
# DOING POST REQUEST TO GET THE DATA
- walk:
to:
post: https://xn--b1afk4ade.xn--90adear.xn--p1ai/proxy/check/auto/history
data:
vin: <%vin%>
captchaWord: ''
checkType: history
reCaptchaToken: <%captcha%>
do:
# PARSE DATA AND SAVE IT TO THE OBJECT
- find:
path: requestresult
do:
- object_new: vehicle
- find:
path: vehicle>enginevolume
do:
- parse
- object_field_set:
object: vehicle
field: engine_volume
- find:
path: vehicle>color
do:
- parse
- object_field_set:
object: vehicle
field: color
- find:
path: vehicle>bodynymber
do:
- parse
- object_field_set:
object: vehicle
field: body_number
- find:
path: vehicle>year
do:
- parse
- object_field_set:
object: vehicle
field: year
- find:
path: vehicle>enginenumber
do:
- parse
- object_field_set:
object: vehicle
field: engine_number
- find:
path: vehicle>vin
do:
- parse
- object_field_set:
object: vehicle
field: vin
- find:
path: vehicle>model
do:
- parse
- object_field_set:
object: vehicle
field: model
- find:
path: vehicle>category
do:
- parse
- object_field_set:
object: vehicle
field: category
- find:
path: vehicle>type
do:
- parse
- object_field_set:
object: vehicle
field: type
- find:
path: vehicle>powerhp
do:
- parse
- object_field_set:
object: vehicle
field: power_hp
- find:
path: vehicle>powerkwt
do:
- parse
- object_field_set:
object: vehicle
field: power_kwt
- find:
path: vehiclepassport>number
do:
- parse
- object_field_set:
object: vehicle
field: passport_number
- find:
path: vehiclepassport>issue
do:
- parse
- object_field_set:
object: vehicle
field: passport_issued
- find:
path: ownershipperiod
do:
- object_new: ownership
- find:
path: from
do:
- parse
- object_field_set:
object: ownership
field: from
- find:
path: to
do:
- parse
- object_field_set:
object: ownership
field: to
- find:
path: simplepersontype
do:
- parse
- object_field_set:
object: ownership
field: owner_type
- find:
path: lastoperation
do:
- parse
- object_field_set:
object: ownership
field: operation_type
- object_save:
name: ownership
to: vehicle
- object_save:
name: vehicleIf we run it on the Diggernaut platform (of course, you will have to use your 2Captcha API key in the web scraper code), then we will get the following data (here’s an example of the dataset in JSON format)
[{
"vehicle": {
"category": "В",
"color": "ЧЕРНЫЙ",
"engine_number": "080571",
"engine_volume": "2967.0",
"model": "ФОЛЬКСВАГЕН ТОUАRЕG",
"ownership": [
{
"from": "2008-05-22T00:00:00.000+04:00",
"operation_type": "11",
"owner_type": "Natural",
"to": "2011-12-10T00:00:00.000+04:00"
},
{
"from": "2011-12-10T00:00:00.000+04:00",
"operation_type": "06",
"owner_type": "Natural",
"to": "2017-02-02T00:00:00.000+03:00"
},
{
"from": "2017-02-02T00:00:00.000+03:00",
"operation_type": "03",
"owner_type": "Natural"
}
],
"passport_issued": "ТАМОЖНЯ: 10009191",
"passport_number": "78ТУ623619",
"power_hp": "224",
"power_kwt": "164.8",
"type": "21",
"vin": "WVGZZZ7LZ8D050320",
"year": "2008"
}
}
]
