Project: Suppliers
Scraped Data
Each digger launch leads to the creation of a new session. All data collected by the digger during the run from the source site will be stored directly in this session.
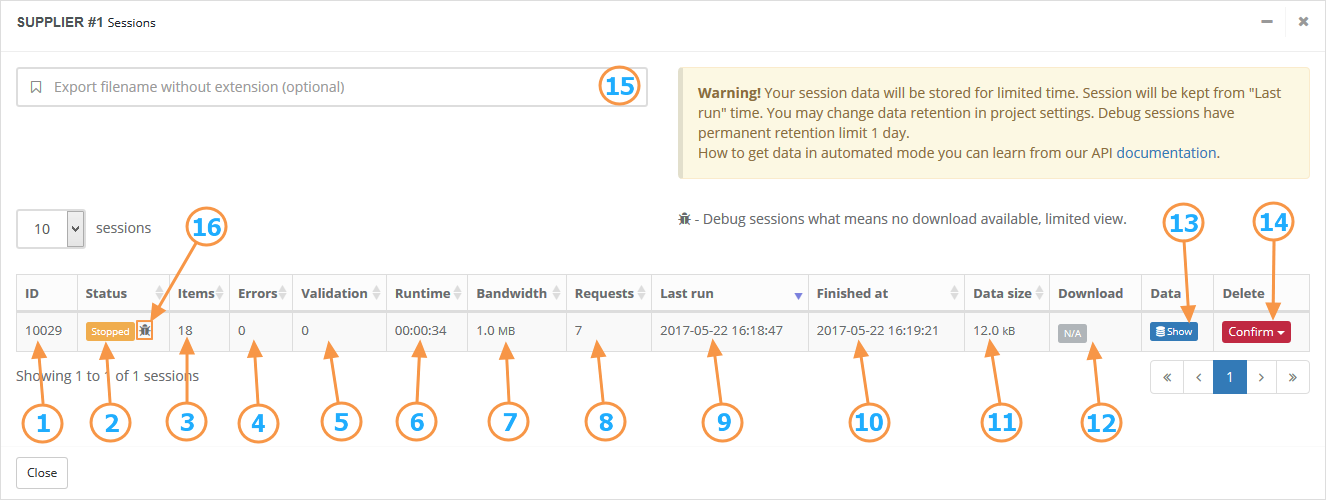
- Session ID
- Session status
- Number of records
- Number of general errors
- Number of validation errors
- Total runtime
- Bandwidth
- Number of page requests
- Start time of digger session
- End time of digger session
- Data size
- Format selector for download
- Data review
- Delete session
- Common filename for exporting (optional)
- Debug marker for session, shown if digger was run in Debug mode
Session ID - used to work with specific session through API. You can also use it when contacting customer support, if you have any questions and our specialist will need to look at the data.
Session status - value depends on if and how the digger completed the job. Can have several states:
Running - digger is currently running, session is not complete
Success - digger finished job, session successfully completed
Failure - digger halted by the system, session failed
Stopped - digger stepped by user, session completed prematurely
Number of records - total number of root objects in the database, gathered by the digger.
Number of general errors - shows the errors that occurred during the execution of the digger configuration. Includes errors happened when digger tries to access the website and errors happened during the run of the digger.
Number of validation errors - shows if some data records had a problems. These errors arise only when the digger has a JSON Schema Validation set and some data records didnt pass validation. For more details, see Data Validation section.
If the session is completed and the digger was run in the Active mode, Format selector for download will be available.
 At this moment our service supports following formats:
At this moment our service supports following formats:
TXT - this is a common text format where the data blocks (records) are separated by three characters -,
The names of the fields consist of the name of the root element and the name of the field separated by >> characters.
The values are separated by the : sign

HTML - html format presents data in table view

CSV, CSV (flat), Excel и Excel (flat) formats let you get data in the form of Comma-Separated Values (fields are separated by comma) or as a binary file for the Microsoft Excel. Both formats (CSV, Excel) has additional option - flat, with flatten data structure. Since the digger script allows you to collect data using nested structures and if your dataset is nested, when you select this option, every nested element (object) generate a new row with data, while parent data is still same for such objects, so it will be duplicated in the rows. For a better understanding, let's look at an example based on a special digger configuration:
---
# Nested data structure sample
config:
agent: Firefox
debug: 2
do:
- walk:
to: https://www.diggernaut.com/sandbox/table-nested-data-en.html
do:
- find:
path: table.main
do:
- object_new: item
- find:
path: tr.title
do:
- find:
path: h2
do:
- parse
- object_field_set:
object: item
field: title
- find:
path: p
do:
- parse
- object_field_set:
object: item
field: description
- find:
path: tr.course > td > table
do:
- find:
path: tbody > tr
do:
- object_new: activity
- find:
path: td:nth-child(1)
do:
- parse
- object_field_set:
object: activity
field: id
- find:
path: td:nth-child(2)
do:
- parse
- object_field_set:
object: activity
field: date
- find:
path: td:nth-child(3)
do:
- parse
- object_field_set:
object: activity
field: age
- object_save:
name: activity
to: item
- object_save:
name: item
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Diggernaut | Meta-language | Nested data structures sample</title>
</head>
<body>
<table width="100%" border="1" class="main">
<tr class="title">
<td>
<h2>Title #1</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit,
sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.</p>
</td>
</tr>
<tr class="course">
<td>
<table width="100%" border="1">
<thead>
<tr>
<th>Activity</th>
<th>Dates</th>
<th>Ages</th>
</tr>
</thead>
<tbody>
<tr>
<td>362000-00</td>
<td>01/10/16 - 14/10/16</td>
<td>6 years to under 9 years</td>
</tr>
<tr>
<td>362000-01</td>
<td>10/11/16 - 24/11/16</td>
<td>9 years to under 11 years</td>
</tr>
<tr>
<td>362000-02</td>
<td>18/12/16 - 30/12/16</td>
<td>11 years to under 13 years</td>
</tr>
</tbody>
</table>
</td>
</tr>
</table>
</body>
</html>
After running digger in Active mode, we will have a session with record number equal to 1.
Now let's download this data by selecting the Excel format.

As you can see, when choosing this format, the data was transformed to three lines (records) instead of one. In this case, the information in the columns title and the description is the same for all records (each activity ID).
Now let's try to download the data in the Excel (flat) format.

Notice how the data has changed. Now they are presented in the form of a flat structure in one line, and the field names contains an additional index in the form of a digit.
You can use one of these flatten algorythms to convert nested data to the flat representation, choosing format which is more convinient for your needs.

XML - format with a simple formal syntax, usually used by other applications for document processing, but also can be
used by human for reading data manually. More details about this format are available on the Wikipedia.

In addition to this data format, Diggernaut provides the ability to create and use special export templates. With these templates you can build your own data representation, of any kind. We will review this feature in the export templates section.
JSON and JSON (pretty) - a text format for data exchange heavily used in JavaScript.
Due to its conciseness in comparison with XML, the JSON format can be more suitable for serializing complex structures. More detailed information on this
format can be found on Wikipedia or on json.org.
The difference between JSON and JSON (pretty) is the second option will be pretty printed and much more
human-readable, while first option has all data compacted to single line.

NDJSON - Similar to JSON, but data records are separated by new line there. You can read more about this format at the ndjson.org

NDJSON (no root) - same as NDJSON, but without root element.

Data review - let you quick check scraped dataset in JSON format right on web page, without downloading data.

- Warning about limitations if session was run in debug mode
- Folded data (to expand, you can click your mouse on the squares)

- Root data element
- Title of the data field
- Value of the data field
- Quick links to the sessions and data tables
Common filename for export - the field is intended for setting a common filename for exporting any of the digger sessions in any format. By default, Diggernaut will name datafiles using following scheme digger_DiggerID_session_SessionID.format, where DiggerID is diger ID, SessionID is session ID and format is selected format. If you enter the value products_for_store to this field, then when exporting, the system will return data with the filename as products_for_store.format.
Session marker - indicates what digger mode (Active or Debug) was used for specific session.
The presence of a marker means that the data was collected in the Debug mode. This mode imposes certain restrictions, namely:
- you can not download data;
- when reviewing data, only the first 20 entries will be available;
If you need a full view of the data or export it to the format you need, put the digger in Active mode and start it again.
When digger finish the job, you will see that new session has not this debug marker.